About the Project

The CAPTCHA (Completely Automated Turing test to tell Computers and Humans Apart) is found throughout many websites. By challenging users to read a line of scrambled letters, identify crosswalks in an image, or some complete another task that is difficult for a computer to do, but comparatively trivial for a human user, a CAPTCHA verifies that the user is an actual human, and not software meant to interact maliciously with the website. This mundane and easily overlooked interface element is an important site where corporate interests and priorities act upon the people who encounter it. CAPTCHAs operate under the assumptions that difference can be detected and that it should be enforced. Because not all humans are able to solve a CAPTCHA, the test additionally enforces a boundary between humans and users.
Google’s reCAPTCHA, a widely used implementation of a CAPTCHA challenge, is a place where the relationship between a Web user and a Web platform is negotiated. Through this conflict, one version of what it means to be an ‘ideal’ Web user is constructed. While the test claims to distinguish between humans and computers, the fact remains that not all humans have the same ability to solve reCAPTCHA challenges. Yet to be able to access content or interact with a website – in effect, to become a user – we must successfully complete these challenges. In effect, the reCAPTCHA not only distinguishes between humans and computers, but also establishes which humans are considered authentic or desirable as users.
Preserving Ephemeral Web Interactions
To analyze Google’s reCAPTCHA, I plan to preserve screenshots and screen recordings of every reCAPTCHA that I encounter during my personal use of the Web from September 1, 2022 through September 1, 2023. From Fall 2021 through Spring 2022, I developed a custom Google Chrome extension which detects when a page contains a reCAPTCHA and prompts the user to save a screenshot or screen recording while also collecting basic metadata. During Summer 2022, I began work on this website to collate and present the screen captures that I save throughout the year. The purpose of collecting these examples of websites where reCAPTCHAs appear is to understand how this Web element is situated within websites and presented to users, along with sketching out the frequency of their use and on what kinds of websites. Given that I will only be collecting records of my own interactions with reCAPTCHAs, this will not be a comprehensive sample that I can generalize as representative of all Web users. Though my experiences of the reCAPTCHA will differ from those of any other person, this collection will nevertheless be useful for demonstrating how the interface element may be embedded within websites and presented to users. Following Niels Brügger’s descriptions of Web history methods, these screen capture techniques provide an effective way to preserve a portion of the Web as it was actually encountered by a person, as opposed to methods such as automated scraping. Therefore my dissertation will offer a methodological contribution to Web historians by demonstrating a technique for identifying and preserving a representation of one Web element within a page, as opposed to focusing an analysis on a whole page or entire website.
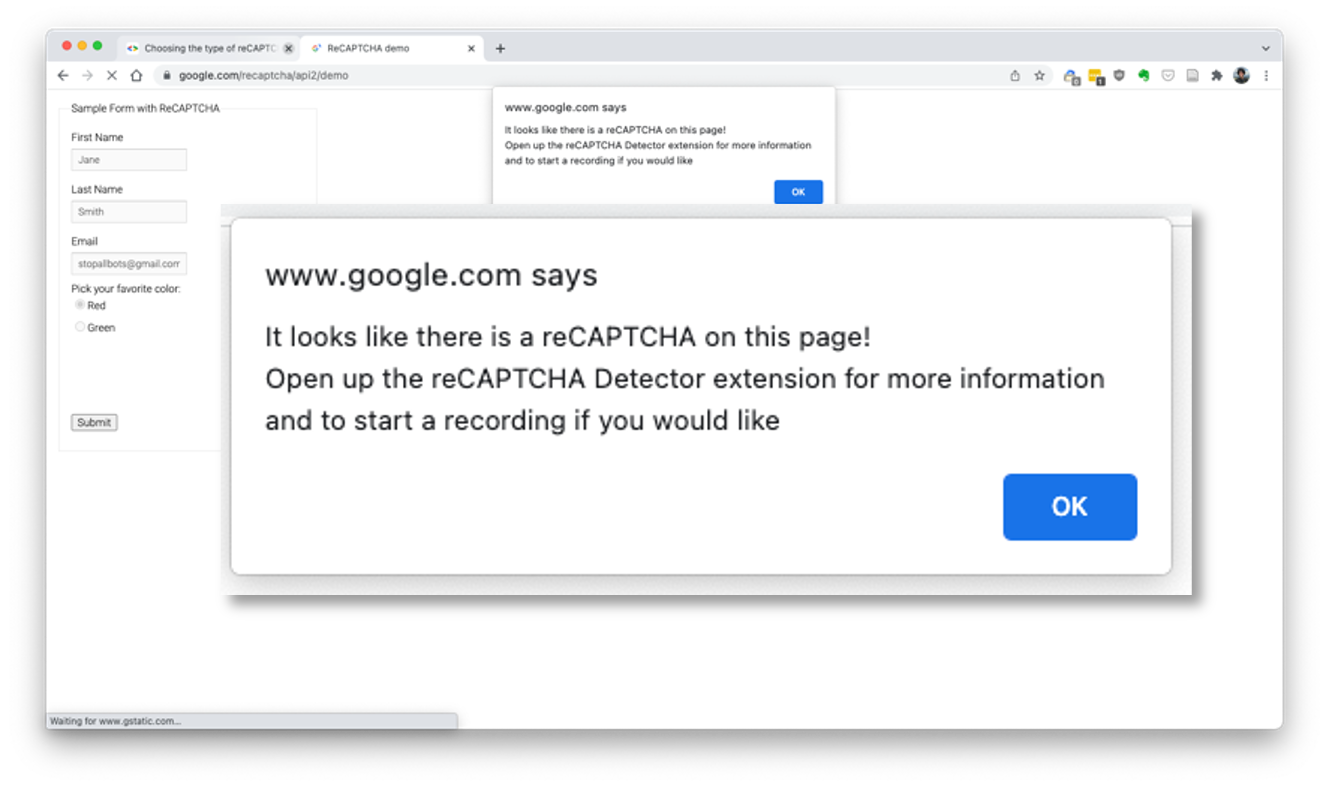
reCAPTCHA examples are collected via a Chrome extension that detects the presence of reCAPTCHAs on a Web page and invites the user to record and preserve their interaction. By detecting specified HTML elements within a Web page, the extension enables researchers to preserve users’ interactions with an interface without needing to continuously (and invasively) record their browsing. The extension aims to balance the priorities of Web preservation with user privacy and autonomy. The presentation will conclude with a discussion of how this extension represents a new approach to Web preservation that may be useful to other digital humanities projects by attending to ephemeral user interactions that other preservation tools are not as well-suited for.
Because this project may be useful as a model for future internet studies project, I have made the code for the Chrome extension publicly accessible. It is published via GitHub and released under a GNU license so that others can use and modify the code within their own projects.
Clone or Fork a Copy of the Code:
https://github.com/bpettis/html-search-and-record
I have configured my installation of the Chrome extension to upload files and submit form data via HTTP to a Google Cloud Function. This function parses the data—saving the uploaded files to a Google Cloud Storage Bucket and writing the data to a database hosted in MongoDB Atlas. Once the data is in the database, it is displayed for the web in a Ruby on Rails App (the website that you're looking at right now)
reCAPTCHAs and Accessibility
In an article published in Convergence, I analyze the discourses of Google’s reCAPTCHA and argue that this common interface element is a multi-faceted site of production where user labor is extracted every time they solve a reCAPTCHA. The products of this labor are threefold: (1) spam reduction, (2) artificial intelligence and machine learning training data and (3) an ideal of a normative web user. This last product is often overlooked but has widereaching implications. Users who solve reCAPTCHAs are producers but simultaneously are produced as users by the reCAPTCHA. The only humans who qualify as ‘authentic’ users are those who can perform this productive labor. Because Google’s reCAPTCHA operates as a site of invisible digital labor, this article works toward making such labor more visible so that users can become more aware of the work they are being asked to perform, and to what ends.
The handful of seconds that go into solving a reCAPTCHA can have important repercussions. The foundational premise of all CAPTCHAs is an assumption that there is a detectable difference between humans and computers. Yet, each challenge also defines and enforces differences between humans users – that is, between unacceptable and desirable users of a website and between people who can perform labor and those who cannot. While all computer technologies are experienced by individual people in different ways, a system’s affordances and functions will nevertheless delineate identities and prescribe certain modes of interaction (McNeil, 2019). As Ellen Rose (2003:7) explains, ‘the moment we sit down in front of a computer, we become enmeshed in a social network of assumptions and ideologies that constructs us not as autonomous and diverse entities existing within diverse social contexts but as a single entity: the User’. By distinguishing between humans and computers, each reCAPTCHA challenge is comparing an individual person to an idealized version of this singular ‘User’ entity. Because reCAPTCHAs are not experienced similarly by everyone who encounters them, this easily overlooked website element contributes to the construction of an ideal Web user.
There have been limited responses to these accessibility and usability problems, such as the development of audio-based CAPTCHA challenges. However, these alternatives tend to be a significantly worse user experience, requiring much more time and having a lower success rate for humans to solve (Lazar et al., 2012). Additionally, these audio CAPTCHAs still fail to accommodate people with intersectional disabilities, such as deaf-blind users (Wentz et al., 2017). There has been some initial work toward the development of CAPTCHA challenges with improved accessibility and usability, but these versions have yet to be widely implemented (Lazar et al., 2012). Google’s reCAPTCHA remains the dominant CAPTCHA used throughout the Web, and it has yet to incorporate these types of improvements.
reCAPTCHAs and the "Becoming-User"
In one chapter of my dissertation, I will use a case study of Google’s reCAPTCHA and argue that the software is one element that can be located within other websites that works to construct an ideal Web user as a person who is able to perform productive labor by providing AI/ML training data. Yet by distinguishing between humans and computers, each reCAPTCHA challenge is comparing an individual person to an idealized version of this singular “User” entity. Because reCAPTCHAs are not experienced similarly by everyone who encounters them, this easily overlooked website element contributes to the construction of an ideal Web user which does not fully represent all people who use the Web on a regular basis. This chapter, then, clarifies how my understanding of the becoming-User provides a perspective on the power hierarchies of the internet. The inclusion of a reCAPTCHA on a page extends Google and Alphabet’s corporate interests into the online space of another website, which shows that the meaning of an ideal User varies from website to website and is continually being reshaped by various stakeholders along with individual people.
This chapter considers how a person becomes a User through mundane interactions with small interface elements within other websites. Where are the places that a person becomes a User? How is the subject-position of the becoming-User presented to individual people? To what extent does a person who uses the Web become aware of the ways that they are constructed as a User?